Cache란?
Cache란 자주 사용하는 데이터값을 미리 복사 해놓는 임시 저장소를 가르킵니다.
Cache 를 사용한 프로그램 동작 방식
Cache 는 나중에 요청된 결과를 미리 저장해두었다가 빨리 제공하기 위해 사용한다.
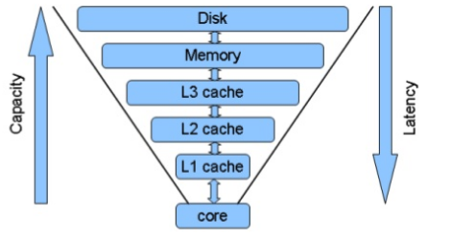
위 그림에서 보다싶이 위로 갈수록 비용도 싸고 용량은 커지지만 접근 속도가 느려집니다.
로그인을 예를 들어보겠습니다.
특정서비스에 로그인을 할시 유저 정보를 디스크에서 가지고 오면 속도가 굉장히 느리지만 메모리에서 가지고 올시 속도가 그만큼 빠를것입니다.
그렇다면 모든 내용을 메모리에 저장하면 좋지 않을까라는 생각을 하게 되는데 메모리는 디스크에 비해 용량 대비 가격이 매우 비쌉니다.
하지만 여기서 파레토의 법칙이라는 글을 읽게 되는데 파레토의 법칙이란 전체의 80퍼센트의 요청이나 부하가 상위 20퍼센트의 유저로 인하여 발생하는 또 그 20퍼센트의 요청중에 상위 80퍼센트는 그안의 20퍼센트에 의해 발생하는 법칙입니다.
그래서 자주 접근하는 정보만 Cache 하더라도 굉장한 효과를 가질수 있다고 합니다.
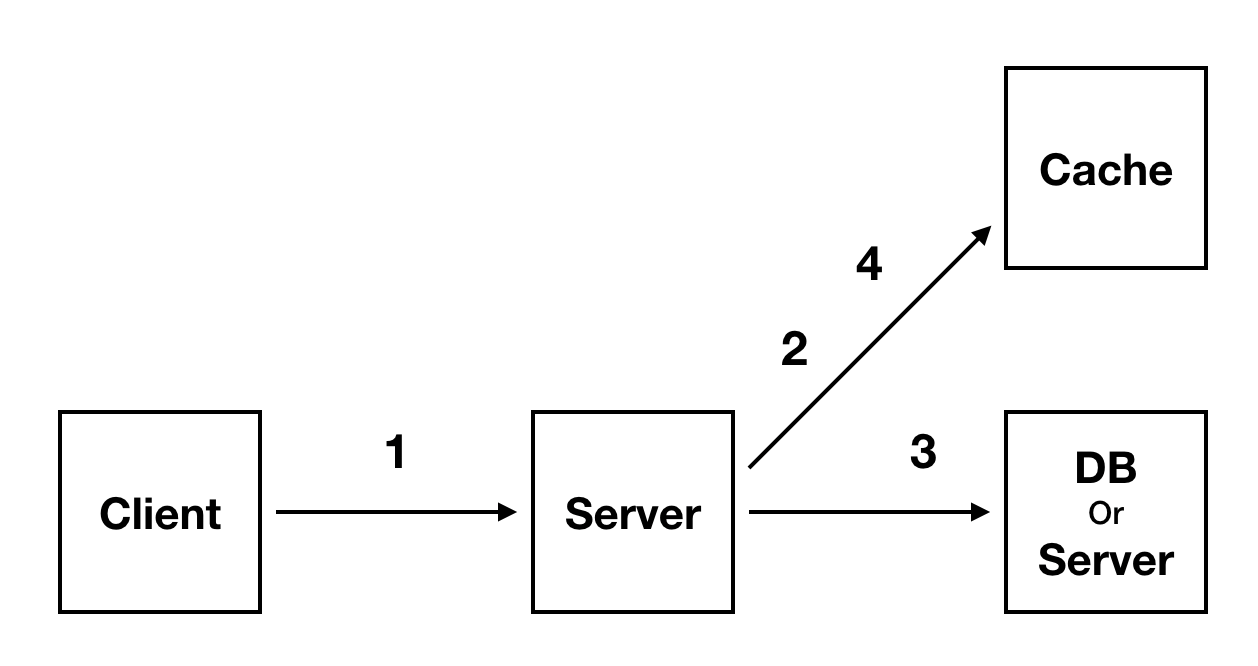
- 클라이언트로부터 요청을 받는다.
-
Web Server 는 데이터가 존재하는지 Cache 를 연계 확인하여 데이터가 있으면 Cache 에서 데이터를 가져옵니다.
→ Cache Hit
-
Cache 에서 데이터가 없다면 DB 에서 데이터를 읽어옵니다.
→ Cache Miss
- DB 에서 읽어온 데이터를 Cache 에 다시 저장합니다.
캐시 사용 방법
1. Look Aside Cache (Lazy Loading)
- 캐시에 데이터 존재 유무 확인
- 데이터가 있다면 캐시의 데이터 사용
- 데이터가 없다면 캐시의 실제 DB 데이터 사용
- DB에서 가져 온 데이터를 캐시에 저장
Look Aside Cache 는 캐시를 한 번 접근하여 데이터가 있는지 판단한 후, 있다면 캐시의 데이터를 사용하고 없으면 실제 DB 또는 API 를 호출합니다. 대부분의 캐시를 사용한 개발이 해당 프로세스를 따릅니다.
2. Write Back
- 모든 데이터를 캐시에 저장
- 캐시의 데이터를 일정 주기마다 DB에 한꺼번에 저장 (배치)
- DB에 저장한 데이터를 캐시에서 제거
Write Back 은 주로 쓰기 작업이 굉장히 많아서, INSERT 쿼리를 일일이 날리지 않고 한꺼번에 배치 처리를 하기 위해 사용합니다. DB에서 디스크를 접근하는 횟수가 줄어들기 때문에 성능 향상을 기대할 수 있지만, DB에 데이터를 저장하기 전에 캐시 서버가 죽으면(리부팅) 데이터가 유실된다는 문제점이 있습니다. 로그를 DB 에 저장하는 경우와 극단적으로 Heavy 한 데이터를 저장하는 경우 사용합니다.
Redis 란?
- Redis 는 Memcached 와 비슷한 캐시 시스템으로서 동일한 기능을 제공하면서 영속성, 다양한 데이터 구조와 같은 부가적인 기능을 지원하고 있습니다.
- In-memory (모든 데이터를 메모리에 저장) 기반 ‘Key-Value’ 기반의 데이터 관리 시스템입니다.
- String, Set, Sorted Set, Hash, List 등의 여러 자료구조를 지원하는데, 서비스의 특성이나 상황에 따라 이걸 1) 캐시 로 사용할 수도 있고, 2) Persistence Data Storage 으로 사용할 수도 있습니다.
Redis의 특징
- 영속성을 지원하는 인 메모리 데이터 저장소
- 다양한 자료 구조를 지원(String, Bitmaps, Set, Sorted Sets, Lists 등)
- 싱글 스레드 방식으로 인해 연산을 원자적으로 수행이 가능
- 읽기 성능 증대를 위한 서버 측 리플리케이션 지원
- 쓰기 성능 증대를 위한 클라이언트 측 샤딩 지원
Redis 특징 1. 영속성
Redis 는 영속성을 보장하기 위해 데이터를 디스크에 저장할 수 있습니다. 서버가 내려가더라도 디스크에 저장된 데이터를 읽어서 메모리에 로딩합니다. 데이터를 디스크에 저장하는 방식은 크게 두 가지가 있습니다.
- RDB(Snapshotting) 방식
- 순간적으로 메모리에 있는 내용 전체를 디스크에 옮겨 담는 방식
- AOF(Append On File) 방식
- Redis의 모든 Write/Update 연산 자체를 모두 로그 파일에 기록하는 형태
Redis 특징 2. Collection
Redis 가 다양한 자료구조 (Collection) 를 지원함으로서 개발자는 비즈니스 로직에만 집중할 수 있습니다.
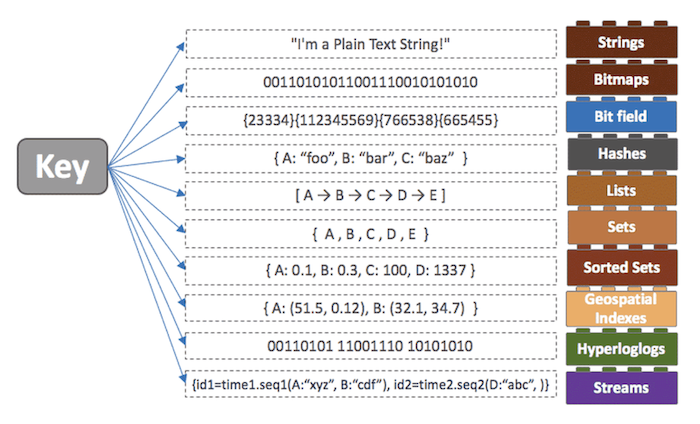
-
String가장 일반적인 형태로, key - Value 로 저장하는 형태이다.
-
Set중복된 데이터를 담지 않기 위해 사용하는 자료구조입니다.
-
ListArray 형식의 데이터 구조이며 List 를 사용하면 처음과 끝에 데이터를 추가 삭제하는 속도가 빠르지만 중간에 데이터를 삽입하거나 삭제하는 경우에는 어려움이 있습니다.
-
Sorted Set유저 랭킹 보드와 같은 서비스 구현에서 사용할 수 있습니다.
데이터 삽입 :
ZADD <key> <score> <value>데이터 조회 :
ZRANGE <start> <end>,ZREVRANGE < start> <end>select * from rank order by score limit 50, 20;
→ zrange rank 50 70
- Sorted Set의 Score 은 double 타입이기 때문에, 값이 정확하지 않을 수 있습니다.
Collection 은 분명 편리하지만 사용할 때 주의할 점도 있습니다.
-
하나의 컬렉션에 너무 많은 아이템을 담으면 좋지 않습니다.
가능하면 10000개 이하의, 몇 천개 수준의 데이터 셋을 유지하는게 Redis 성능에 영향 주지 않습니다.
-
Expire 은 Collection 의 아이템 개별로 걸리지 않고, 전체 Collection 에 대해서만 영향을 줍니다. 즉, 10000 개의 아이템을 가진 Collection 에 expire 가 걸려있다면, 그 시간 이후에 10000 개의 아이템이 모두 삭제됩니다.
Redis 의 특징 3. Single Thred
Redis 자료구조는 Atomic 하다는 특징때문에 이런 Race Condition 을 피할 수 있습니다. 즉, Redis Transaction 은 한번의 딱 하나의 명령만 수행할 수 있습니다. 또한 Single Thread 특성을 유지하고 있기 때문에 다른 스토리지 플랫폼보다는 이슈가 덜하다고 합니다.
예를 들어, 친구 리스트의 친구를 추가하는 연산을 시도하는 경우 아래와 같이 정상적인 상황에서는 유저 각각의 트랜잭션이 순서대로 잘 행해지고 있으므로 문제가 없습니다.

그러나 동시에 친구 리스트에 B, C를 추가한다고 하면 어떨까요?

두 트랜잭션이 동일한 최종 상태인 A를 자신의 메모리로 읽어 들이고, 그 상태에서 각자 B 또는 C를 추가하게 되면 최종 상태가 (A, B) 혹은 (A, C)가 된다. (A, B) 혹은 (A, C)라고 한 이유는 컨텍스트 스위칭에 따라 두 트랜잭션 중 누가 먼저 끝날 지 예측할 수 없기 때문입니다. 물론 이러한 Race Condition 을 해결하기 위해 격리 수준 등 여러 가지 기법이 있지만, Redis는 싱글 쓰레드를 사용하므로 하나의 트랜잭션은 하나의 명령만 실행할 수 있으므로 다수의 Race Condition 을 해결할 수 있습니다. (더블 클릭 이슈는 싱글 쓰레드만으로 불가능)